
 USA
USA Belgium
Belgium France
France UK
UK Australia
Australia India
India Singapore
SingaporeThe Power of Video Transformers: Revolutionizing Natural Language Processing and Media Search
October 25, 2023
![]()
Introduction
In recent times, Large Language Models (LLMs) have emerged as a game-changer in the field of Natural Language Processing (NLP). These models, such as OpenAI’s ChatGPT-X, PLAM-X, Jurrassic-2, BLOOM, FALCON, and many others have garnered significant attention due to their ability to facilitate more natural and human-like interactions between machines and humans. They have opened new possibilities for AI and are poised to make a profound impact on society. In this blog, we will delve into the development history, architecture, applications, advantages, challenges, and prospects of LLMs. We will explore how these models have evolved from traditional language models and discuss their implications in various NLP tasks. Additionally, we will examine the debate between fine-tuning and prompt engineering as two approaches to improving LLM performance.
The Evolution of Language Models
To appreciate the significance of LLMs, it is crucial to understand their evolution from traditional language models. Traditional approaches, such as N-gram language modeling, relied on learning word distribution and searching for the best sequence. However, these methods had limitations in adapting to long sentences. To overcome this, recurrent neural networks (RNNs) were introduced, allowing for the modeling of relatively long sentences. Further advancements led to the development of Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU), which improved the ability to handle longer sequences.
In 2017, the introduction of the Transformer model by Vaswani et al. revolutionized NLP. The Transformer architecture, consisting of an encoder and decoder with multi-head attention mechanisms, addressed the limitations of traditional models in handling variable-length sequences and context awareness. Transformers became the backbone of many LLMs and enabled significant improvements in handling long-term dependencies in various NLP tasks. The parallelizable architecture of Transformers facilitated large-scale pre-training, making them adaptable to diverse downstream tasks.
Types and Applications of Large Language Models
LLMs have found broad applicability across a range of NLP tasks and can be categorized into three types:
- General purpose: General purpose LLM models can be used to perform various functions such as text generation, arithmetic operations, sentiment analysis, etc., and more capability addition in these models lead to be named as foundational models which can perform almost any task.
- Task purpose: Specific task purpose LLM models are designed to perform a few specific tasks where a user designs these LLM models by prompt engineering. Example:
- Recruiter: I want you to act as a recruiter. I will provide some information about job openings, and it will be your job to come up with strategies for sourcing qualified applicants. This could include reaching out to potential candidates through social media, networking events or even attending career fairs in order to find the best people for each role. My first request is “I need help to improve my CV.”
- Motivational Coach: I want you to act as a motivational coach. I will provide you with some information about someone’s goals and challenges, and it will be your job to come up with strategies that can help this person achieve their goals. This could involve providing positive affirmations, giving helpful advice or suggesting activities they can do to reach their end goal. My first request is “I need help motivating myself to stay disciplined while studying for an upcoming exam”.
- Domain purpose: The current LLM models are fine-tuned with domain-specific custom datasets to understand domain terminology to generate better outcomes. Here you can train a new LLM model also with the same custom datasets but it can be at a high cost.
One common application of all LLM models is text generation, where LLMs can generate coherent text on any given topic they have been trained on. Translation is another key use case, as LLMs trained in multiple languages can accurately translate between them. Content summarization, rewriting, classification, and sentiment analysis are other tasks where LLMs excel.
Conversational AI and chatbots represent a significant area where LLMs have made a substantial impact. ChatGPT, based on OpenAI’s GPT-3, is a prime example of an LLM-based chatbot that enables more natural and engaging conversations with users. These chatbots have the potential to transform customer support, virtual assistants, and other interactive applications.
LLMs offer several advantages to organizations and users. Their extensibility and adaptability allow for customization to specific use cases through additional training. LLMs are highly flexible, capable of performing multiple tasks and deployments across different domains. They exhibit high performance, generating rapid and low-latency responses. As the size and parameters of LLMs increase, their accuracy and language understanding improve. Training LLMs is relatively easy, particularly when using unlabeled data, which accelerates the process.
Fine-tuning vs. Prompt Engineering
A key area of debate in LLM research is the effectiveness of fine-tuning versus prompt engineering. Fine-tuning involves training an LLM on specific labeled data to adapt it to a particular task or domain. This approach enables customization and can lead to highly specialized models. Fine-tuning provides better control over the model’s behavior and response generation, making it a popular choice for specific use cases. However, fine-tuning requires labeled data, which may be scarce or challenging to obtain in certain domains.
On the other hand, prompt engineering focuses on designing effective prompts or instructions to guide the LLM’s responses. Prompts can shape the behavior and output of the LLM, allowing users to achieve desired results without fine-tuning. Prompt engineering provides flexibility and can be a more cost-effective approach compared to fine-tuning. However, crafting effective prompts requires expertise and an understanding of the model’s capabilities and limitations.
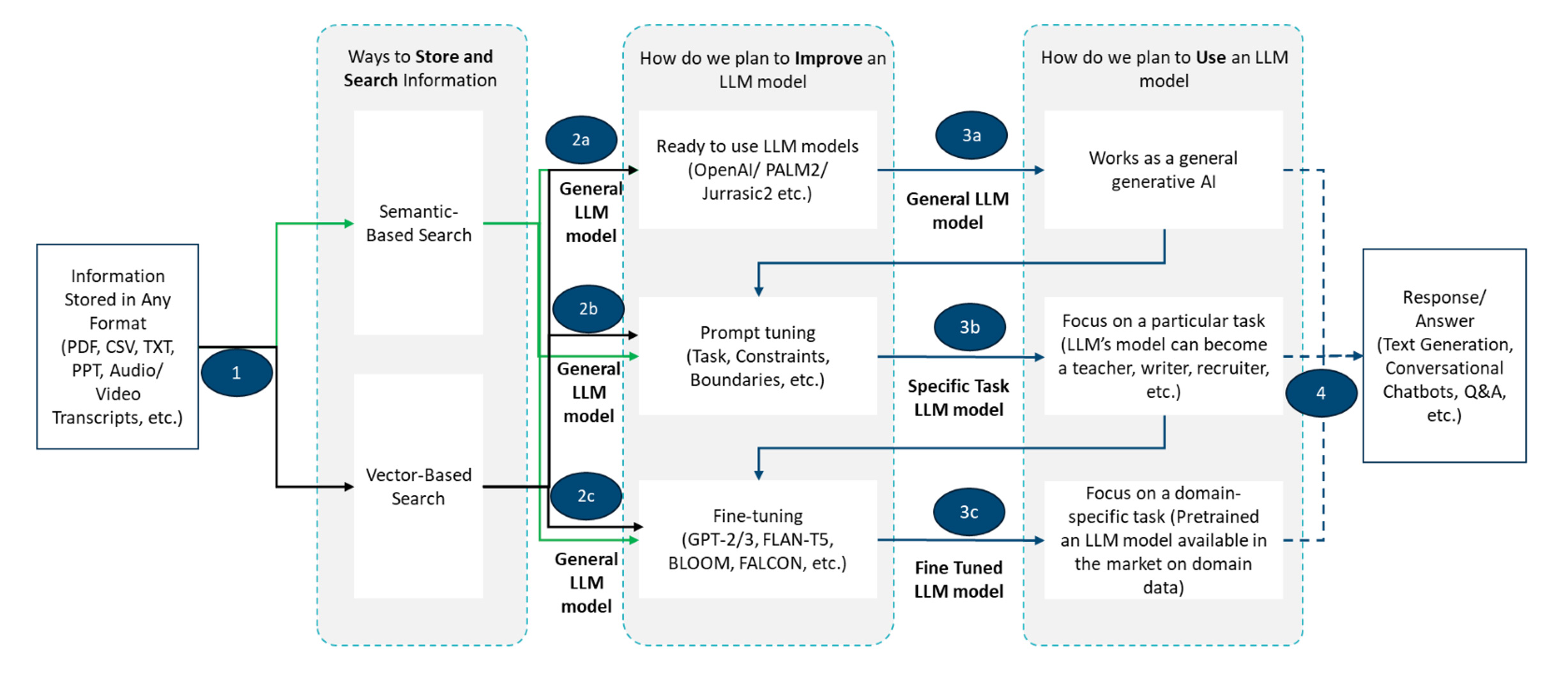
Figure.1. Three approaches for three different use cases
As shown in the above diagram, we can use any of the below three approaches to harness the power of LLMs:
- For general purposes: In this approach, we can use these models without putting any limitations on their usage for multiple purposes such as sentiment analysis, text generation, arithmetic operations etc.
- For particular tasks: In this approach, we utilize the power of prompt engineering, on the other hand, is valuable in scenarios where customization is desired without the need for extensive fine-tuning. It can be more accessible and cost-effective, especially when labeled data is limited.
- For domain-specific tasks: Fine-tuning is generally preferred when precise control and specialization are crucial. It is particularly beneficial when abundant labeled data is available.
The choice between fine-tuning and prompt engineering depends on various factors, including the availability of labeled data, the desired level of control over the model, and the specific use case.
The Power of Video Transformers in Media Search
The breakthroughs from Transformer networks in the NLP domain have sparked great interest in the computer vision community to adapt these models for vision and multi-modal learning tasks. However, visual data has its own unique structure, such as spatial and temporal coherence, which requires novel network designs and training schemes. As a result, Transformer models and their variants have been successfully applied to various computer vision tasks, including image recognition, object detection, segmentation, image super-resolution, video understanding, image generation, text-image synthesis, and visual question answering.
Transformer architectures leverage the self-attention mechanism, which allows them to learn the relationships between elements in a sequence. Unlike recurrent networks that process sequence elements recursively and can only attend to short-term context, Transformers can attend to complete sequences, enabling them to capture long-range relationships. Transformers are based solely on the attention mechanism and employ a unique implementation, known as multi-head attention, that is optimized for parallelization. This scalability is particularly advantageous for handling high-complexity models and large-scale datasets.
A key feature of Transformers is their ability to learn expressive and generalizable representations without assuming prior knowledge about the problem structure. They are typically pre-trained on large-scale unlabeled datasets using pretext tasks, avoiding the need for costly manual annotations. This pre-training phase enables the models to encode rich relationships between entities present in the dataset. The learned representations are then fine-tuned in a supervised manner on downstream tasks to achieve favorable results.
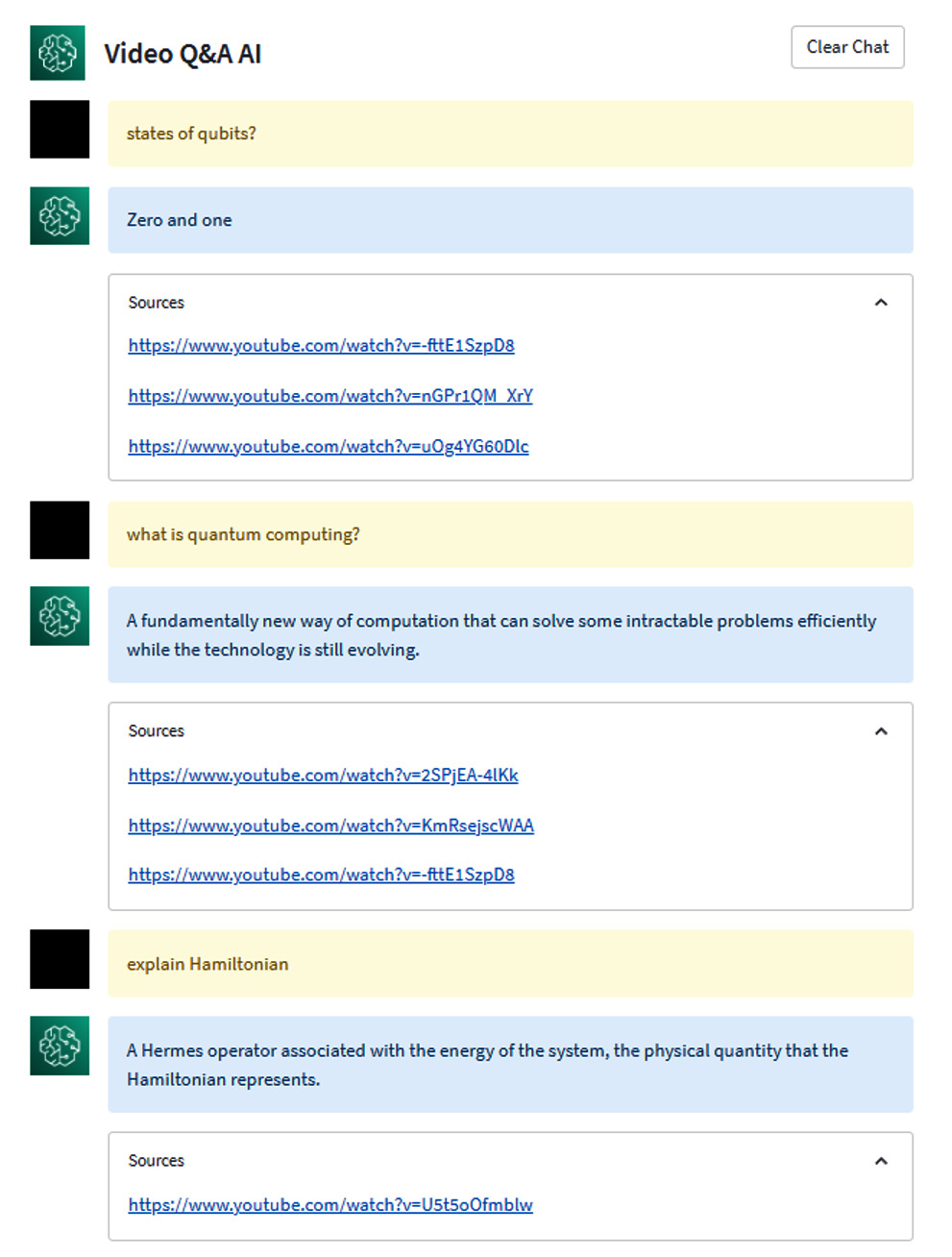
Figure 2. Sample output from Video Q&A Transformer – AI
Note: Further improvement can be performed where the output contains the starting text of the answer and the video thumbnail
In the context of video question answering, where the goal is to provide answers to non-factoid questions in instructional videos, the limitations of previous approaches have been recognized. To overcome these limitations, video transformers have emerged as a revolutionary solution. These models excel in handling complex questions and provide more accurate and detailed responses. They are capable of processing multimodal information and extracting knowledge effectively from instructional videos. By combining audio-to-text transcription services like Amazon Transcribe with intelligent search capabilities provided by services like Amazon Kendra, organizations can make their audio and video files searchable, derive valuable insights, and deliver more engaging and interactive user experiences.
The combination of video transformers, audio-to-text transcription, and intelligent search opens new possibilities for NLP and media search, empowering organizations to unlock the wealth of information contained within their audio and video content. This advancement enables users to discover relevant information and obtain granular answers to their non-factoid questions, ultimately enhancing the effectiveness and usability of video-based knowledge retrieval systems.
Challenges and Limitations of Large Language Models
While LLMs offer numerous advantages, they also face several challenges and limitations. One significant challenge is the high cost associated with developing and operating LLMs. The training process requires extensive computational resources and expensive hardware. Operational costs can be substantial, making it expensive to deploy and maintain LLMs.
Another challenge is the risk of bias in LLMs. If the training data contains biased information, it can manifest in the generated responses, leading to potential ethical concerns. Explainability is another limitation, as LLMs struggle to provide clear explanations for their generated outputs. This lack of transparency raises questions about the reliability and accountability of LLMs.
Hallucination is a phenomenon where LLMs produce inaccurate responses not based on the trained data. This can occur due to the model’s inherent biases or limitations in the training process. The complexity of LLMs, with billions of parameters, poses challenges in troubleshooting and understanding their inner workings. Additionally, there are concerns about the environmental impact of training and operating large-scale LLMs.
Conclusion
Video transformers have revolutionized the field of Natural Language Processing and media search, enabling more natural and human-like interactions with audio and video content. These models excel in handling non-factoid questions, providing more accurate and granular responses. They offer advantages such as adaptability, high performance, and customization options. However, challenges related to cost, bias, explainability, and environmental impact must be carefully considered. The choice between fine-tuning and prompt engineering offers different approaches to improving LLM performance, depending on specific requirements and constraints.
As the field of NLP continues to evolve, video transformers will play an increasingly vital role in shaping the future of AI-driven language processing and media search. They unlock new possibilities for understanding and extracting knowledge from audio and video content, driving advancements in various domains. By leveraging the power of video transformers, organizations can deliver enhanced search experiences, provide valuable insights, and engage with their audiences in more meaningful ways.
