
 USA
USA Belgium
Belgium France
France UK
UK Australia
Australia India
India Singapore
Singapore

The human brain is, undoubtedly, the most extraordinary technology created by nature. An artificial neural network (ANN), modeled after the human brain, is a system software or hardware that performs tasks as the neurons of a human brain would, to an extent, by transferring information along a predefined path between neurons. Artificial neural networks consist of layers of interconnected neurons that receive sets of inputs and weights. They then perform mathematical manipulation and give out a set of activations as an output that is similar to synapses in biological neurons.
Today, neural networks can be used to achieve complex tasks in the fields of machine learning and artificial intelligence (AI), including object recognition, automatic speech recognition (ASR), machine translation, image captioning, video classification, and more.
Even this is a limited list. Artificial neural networks are the most potent learning models in the field of machine learning. They can achieve arguably every task that the human brain can perform, albeit they might work differently than an actual human brain.
Human Brain and Neural Networks – A Comparison
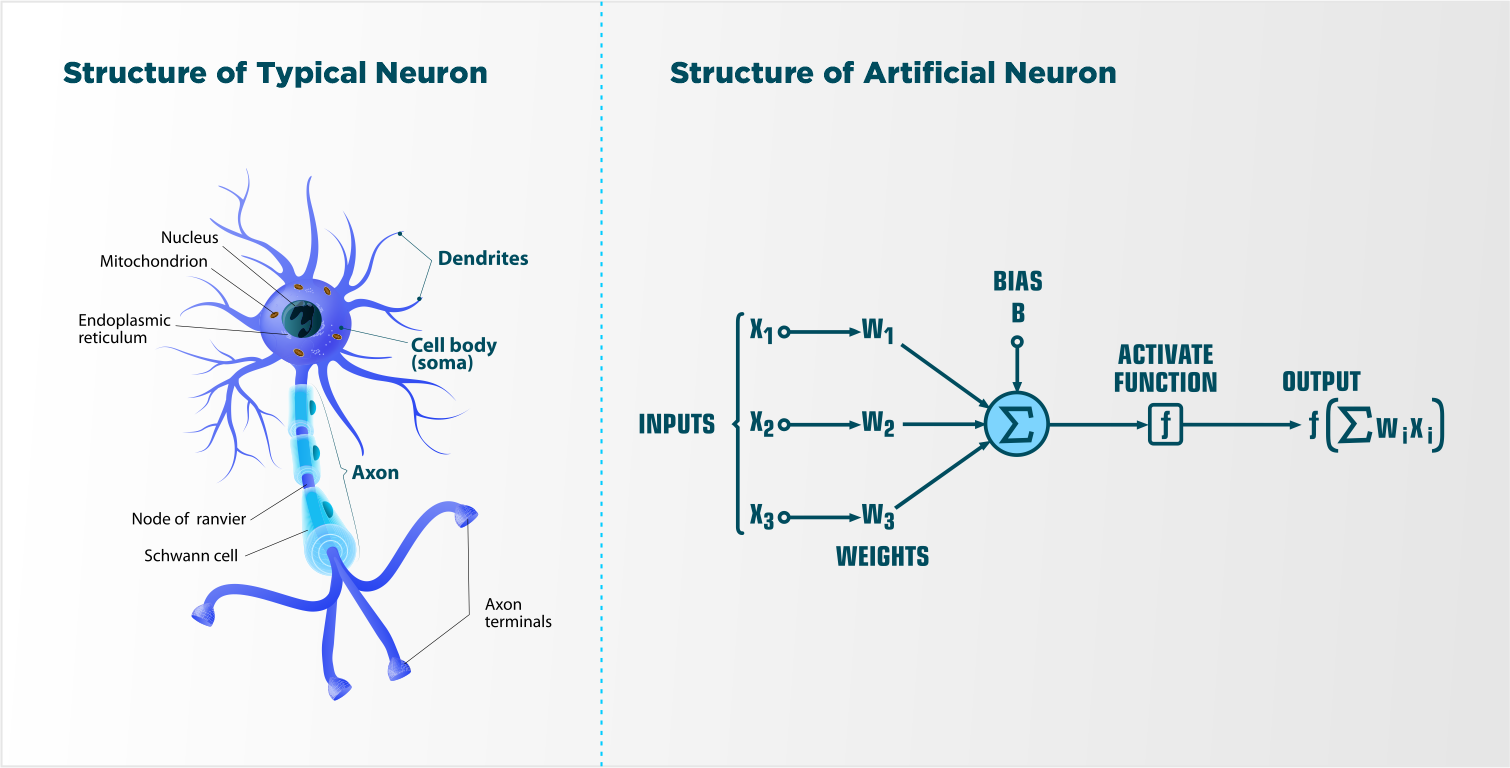
At a high level, neural networks – both artificial and biological – consist of four components:
- Neurons
- Topology – the connecting path between neurons
- Weights
- A learning algorithm
There are substantial differences in each of these components when it comes to biological and artificial neural networks. Some of the key differences are as follows:
- An ANN typically consists of hundreds to at best thousands of neurons, whereas the biological neural network consists of billions of neurons.
- BNNs have trillions of adjustable parameters, whereas even the most complicated ANNs only have several million learnable parameters.
- ANNs primarily use some gradient descent models for learning, whereas when it comes to biological neural networks, even leading neuroscience and cognitive science experts do not have much clarity on the learning methods used.
- The processing speed for biological neurons is usually in milliseconds, whereas standard ANNs can process information much faster (in nanoseconds).
- Natural neural networks have extremely complicated topologies, whereas artificial neural networks have standard and comparatively simple paths.
- Biological neural networks consume significantly lesser power as compared to artificial networks.
How do Neural Networks Work?Essentially, a neuron is a node with several inputs and one output, and many interconnected neurons form a neural network. For neural networks to perform their tasks, they need to go through a ‘learning phase’ – which means they need to learn to correlate incoming and outgoing signals. Once done, they begin to work, i.e., receive input data and generate output signals based on the accumulated information. Biological neurons receive signals through dendrites, which either amplify or inhibit the signals as they pass through the axons to the dendrites of other neurons. Similarly, the ANNs learn to inhibit or amplify the input signals to perform a specific task.
Neural Networks and Deep Learning
More often than not, deep learning developers take into account the features of the human brain— the architecture of its neural networks, learning and memory processes and so on – for their deep learning projects which usually need a massive amount of data to train the system to classify signals clearly and accurately.
In this post, we will try to delve into the basics of neural networks and how they work in the field of deep learning.
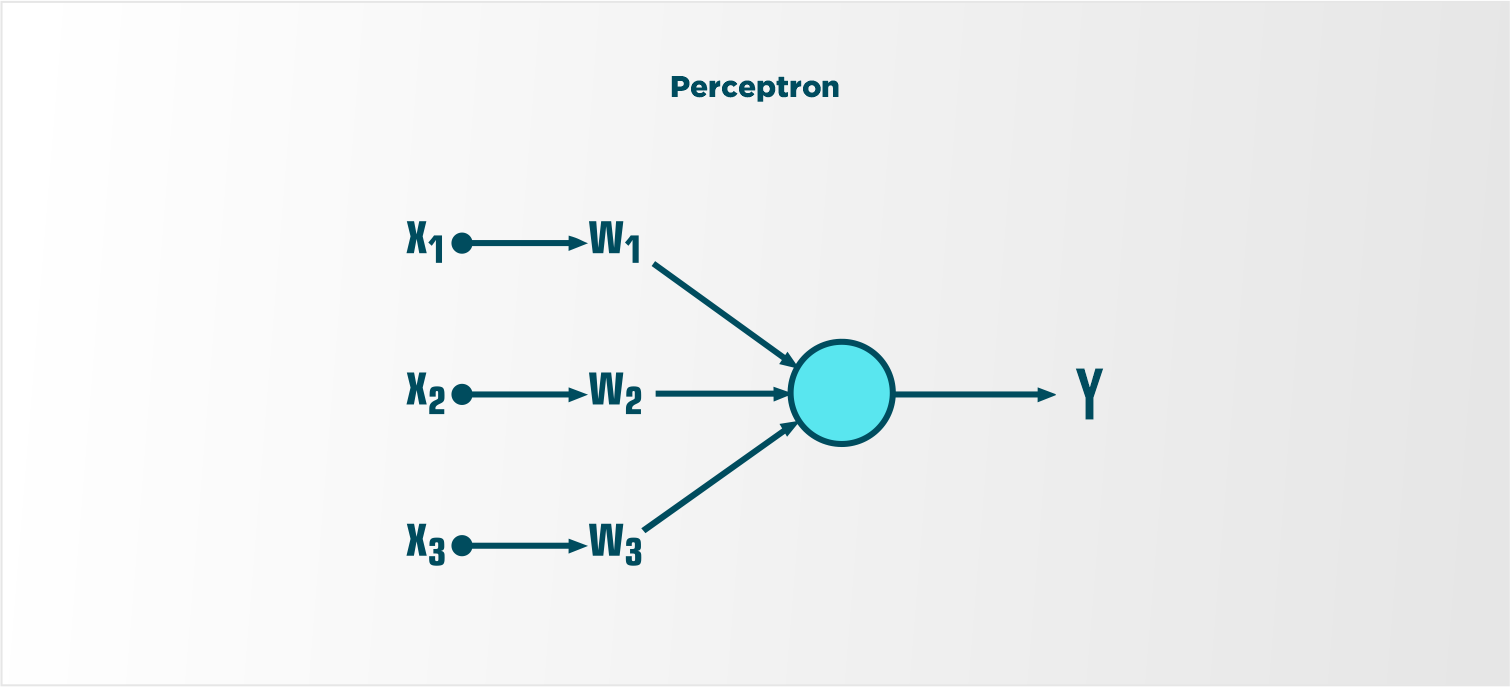
Perceptrons – Earliest Neural Networks
Suppose you want to plan a family trip. From the following factors which are the critical factors for you?
- Trip Expenditure
- Trip Duration
- Hotel Comfort and Cuisine Preference
- Mode of Travelling
How our human brain works is it assigns weight to each of the factors. For one, trip duration may be the most critical factor, while for someone else it might be the trip expenditure. A perceptron works similarly. It takes input signals as inputs and performs a set of simple calculations to arrive at a decision.
Perceptrons can be used in classification tasks as well, where we fit a divider such that it divides the data points into regions. Perceptron can also perform multiclass classification as well. We can use multiple perceptrons where each perceptron classifies data points into various categories.
Training of Perceptron
Now that we know fundamentally what a perceptron is, let’s look at the iterative solution for training the perceptron suggested by Frank Rosenblatt, a notable American psychologist in the field of artificial intelligence. Rosenblatt suggested an elegant iterative solution to train the perceptron (i.e., to learn the weights).
He proposed that we start with random weight and keep on adding the error term to the weight till the time we didn’t find the valid separator. The error term is the misclassified point from the previous separator.
Working of Neurons
Neurons are similar to perceptrons; the only difference being that there is an activation function applied to the weighted sum of inputs.
In perceptrons, the activation function is the step function, though, in artificial neural networks, it can be any non-linear function. Few fundamental properties of neural networks are:
- Neurons in a neural network are arranged in layers where the first and the last layer are called the input and output layers.
- Input layers have as many neurons as the number of attributes in the data set.
- The output layer has as many neurons as the number of classes of the target variable in case of the classification problem.
- The output layer has one neuron in case of the regression problem.
Generally, the industry used neural networks follow the below-mentioned assumptions:
- Neurons are arranged in layers, and the layers are arranged sequentially.
- Neurons within the same layer do not interact with each other.
- All inputs enter the network through the input layer, and all outputs leave the network through the output layer.
- Neurons in consecutive layers are densely connected, i.e., all neurons in layer l are connected to all neurons in layer l + 1.
- Every interconnection in a neural network has a weight associated with it, and every neuron has a bias associated with it.
- All neurons in a particular layer use the same activation function.
It is important to note that the input to a neural network can only be numeric. So how to solve the problem where the input that we have is text (NLP problems) or images (computer vision problems)?
- Text Data as Input: In the case of text data, we either use a one-hot vector or word embeddings corresponding to a particular word. If we need to work with a vast vocabulary, then it is recommended to use word embeddings over one-hot vectors.
- Images as Input: In the case of images (or videos), it is quite straightforward since images are naturally represented as pixels (arrays of numbers), where each pixel of the input image is a feature. If we have a grayscale image of size 18 x 18, the input layer would need 324 neurons. If the image is a colored image, we need 18 x 18 x 3 neurons in the input layer, as the color image needs three channels (red, green, and blue).
Activation Functions
We know that the weighted sum of neuron passes through activation function before it goes as an input to neuron in the next layer. The activation function could be any function, though it should have some important properties such as:
- Smoothness i.e., they should have no abrupt changes when plotted because decision making doesn’t change abruptly based on any factor.
- They should also make the inputs and outputs non-linear with respect to each other to some extent. This is because non-linearity helps in making neural networks more compact.
Few popular activation functions are:
- Logistic function
- Hyperbolic tangent function
- Rectilinear Unit (ReLU)
Training of the Neural Network
The weight and bias of every individual neuron need to train to get the right predictions. Training of neural networks is similar to any other machine learning algorithm like SVM, linear regression, where the objective is to find optimal weights and biases to minimize the loss function, which can be complex even for a simple network. For solving real-world problems, there will be an exponentially large number of weights and biases that need to be minimized. Keeping the mentioned complexity in mind. Let’s see the steps involved in training the neural networks:
- Feedforward: The information flows (or training of the network) in a neural network from the input layer to the output layer.
- Backpropagation: The adjustment of the weights to minimize the loss function.
But that’s a topic for another day when we take a deeper dive into the fundamental building block of artificial neural networks. Note: prerequisites for the next level include a basic understanding of statistical concepts and matrix multiplication.
Conclusion
Artificial Intelligence has, irrefutably, permeated several aspects of our life and has become the new normal. With the increasingly human-level accuracy of performing tasks pattern recognition, image classification, and more, the industry has revolutionized how we connect with machines every day.
A growing body of research and experimentation in the field of deep learning application is gradually normalizing AI into our day-to-day lives in the form of face and speech recognition and self-driving technology, to name a few. So how deep an impact can deep learning have in the digital transformation of businesses and how the world around us works? Human brains are working their neurons hard to push the limits of what artificial neural networks can achieve.
Watch this space for more on deep learning, and it’s applications.
